一、基本信息
1.专业代码:080910W 专业名称:数据科学与大数据技术(大数据实训) 招生时间:2020
2.学科门类:计算机科学与技术 专业分类:工科应用类 所属学院:数据科学与技术学院
3.学制:一年
二、概述
数据科学与技术学院结合国家“十三五”规划纲要中提出要实施国家大数据战略,面向大数据应用领域人才的迫切需求,在“大数据战略人才培养工程”背景下,设置了大数据技术专业方向,培养符合大数据产业发展需求的,能从事数据领域的系统设计、建设、维护与运维管理的应用型工程人才。
学院实现产学研一体化的培养体系,采用“双师双轨式”教学模式,学院多名教师参加企业和行业的专业最新技能培训,参与专业核心技术课程和项目实训课程的讲授。
二、培养目标
专修班采用"技术讲授+实验+案例实训"模式,按照“大数据基础-大数据系统与工具-大数据核心技术”的学习线路,精理论重实践,涵盖了大数据核心技术知识体系:Hadoop生态圈(分布式文件系统HDFS、并行处理的框架MapReduce编程等)、大数据仓库Hive、分布式数据库HBase与核心开发技术Spark等相关知识与工具的学习,掌握大数据前沿领域技术,初步具备大数据工程项目的系统集成能力、应用软件设计和开发能力。具备从事大数据系统开发、集成、维护工作,以及大数据管理、咨询、教育培训工作的知识、能力素质。
1.通过大数据基础、大数据系统与工具的学习,了解大数据体系结构的部署模式,初步掌握大数据平台搭建或部署典型环境、大数据系统开发工具与方法。
2. 通过大数据核心技术的学习,掌握大数据采集、存储、处理与分析、传输与应用等技术,学生可以从“大数据技术的视角”考虑解决方案,具备一定的大数据应用系统的设计、开发和部署的能力。并能够运用大数据模式与技术解决相关专业领域或社会问题的能力。
3.具有正确的人生观、世界观及公民意识;具有良好的职业道德和团队合作精神;具备领导意识和才能;具有较强的工程素养及人文精神;具有健全的人格及较强的社会责任感。
三、课程设置
1. 主要课程
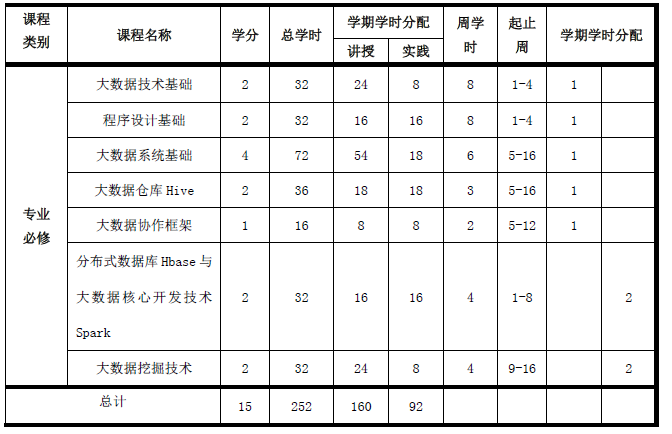
大数据技术基础、程序设计基础、大数据系统基础、大数据仓库Hive、大数据协作框架、分布式数据库Hbase与大数据核心开发技术Spark、大数据挖掘技术。
2. 课程简介
(1)大数据技术基础
数据科学导论:数据科学的理论、方法和技术,以及大数据的各种类型、状态、属性及变化形式和变化规律。
Linux操作系统基础:Linux系统概述、系统安装及相关配置、Linux网络基础、vi文本编辑器、用户和用户组管理、磁盘管理、Linux文件和目录管理、linux系统监测与维护等。
(2)程序设计基础
java程序设计基础:java基础、面向对象、核心API的使用、类和接口、进程与线程、网络编程。
(3)大数据系统基础
大数据体系框架基础:用于存储海量数据分布式文件系统HDFS、分布式资源管理框架YARN、管理集群资源和分布式数据处理框架MapReduce;分布式并行计算框架。Hadoop 2.x的编译、环境搭建、HDFS Shell使用,YARN 集群资源管理与任务监控,海量数据并行处理的框架MapReduce编程,分布式集群的部署管理(包括高可用性HA)等。
(4)大数据仓库Hive
基于Hadoop的数据仓库工具:可将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行,适合数据仓库的统计分析。
(5)大数据协作框架
数据转换工具Sqoop:用于在Hadoop(Hive)与传统的数据库(例如:MySQL,Oracle等)间进行数据的传递,可以将一个关系型数据库中的数据导进到Hive中。
文件收集框架Flume:架构原理、设计、初步使用,实时采集数据,使用Flume监控文件夹数据,实时采集录入HDFS中。
(6)分布式数据库Hbase与e与大数据核心开发技术Spark
非结构化数据存储管理HBase:一个分布式的、面向列的开源数据库,面向列、可伸缩的分布式存储系统,利用HBase技术可在PC Server上搭建起大规模结构化存储集群。包括:HBase Schema、HBase 环境搭建、shell初步使用,表的设计,表的预分区,HBase 表的常见属性设置,HBase Admin操作(Java API、常见命令)等。同时要实践掌握内存计算框架Spark:启用了内存分布数据集,能够提供交互式查询,优化迭代工作负载。包括:Scala程序设计基础,Spark 概述、生态系统、与MapReduce比较,Spark 编译、安装部署(Standalone Mode)及测试,Spark应用提交工具(spark-submit,spark-shell),Spark 核心RDD,Spark on YARN运行原理、运行模式及测试。
(7)大数据挖掘技术
大数据挖掘平台SmartMining:大数据挖掘方法、模型,数据挖掘算法(包括:数据处理类算法、分类预测类算法、聚类算法、关联规则算法、统计算法等),数据挖掘可视化技术(包括:词云、地图、网络图、散点图矩阵等),数据挖掘业务模型(包括:信用评分模型、客户流失模型、专家诊病模型、市场细分模型、媒体分级模型、文本挖掘模型、文本分类模型、微博分析模型等)。
3. 教学计划进程表
五、修读条件
1. 招生对象应为我校一年级以上全日制在校本科生。
2. 学生须学有余力,主修专业无不及格课程,学分绩点不低于6.7。
3. 有计算机语言学习经历,互联网软件开发经历,互联网+大赛、软件程序设计大赛、ACM设计大赛经历的学生优先录取。